

How I Built a Personal Finance AI Assistant with Local Language Models
And what I learned along the way
I’ve always hated the idea of sending my financial data to cloud-based personal finance services. Account names and numbers, transactions, spending habits (and more) reveal intimate details about my life. Once in the cloud, my financial data is for sale and can be used to target me for advertisements or other purposes.
Now I know what you’re thinking — paid personal finance solutions exist, and some allegedly don’t sell or share your data, but some random person still has access to it. They also usually operate on a subscription model, and subscriptions don’t float my boat. I don’t even pay for a music streaming service.
Excel is the next best option, right? It’s fine for most people, but I have a deep seated hatred for Excel, so that won’t work either.
So, I did what any rational human being would do. I built my own iOS budgeting app. Release date TBD.

I’ve Got the Power
With full control over my own budgeting app, I can integrate basically whatever I want.
Ever since modern “AI” entered the public stream of consciousness with ChatGPT, I’ve been dying to utilize the technology for personal finance — being able to quickly answer complicated questions like income or spending trends or forecasting out significant changes in my finances is valuable to me.
The problem? Cloud-based AI APIs aren’t free, and they aren’t private.
Still being my completely rational self, this led me to explore a question: Could I build a useful AI-powered financial assistant that wasn’t cloud-based?
Proof of Concept

Local language models have come a long way from when I first started experimenting with Llama 2 — they’ve become much more intelligent and have dramatically shrunk in parameter size relative to the intelligence of the model.
The ultimate goal for me is on-device inference on an iPhone. To take full advantage of Apple’s hardware and software, I would need to utilize Apple’s CoreML framework. The only problem is that CoreML doesn’t natively support formats like GGUF or GGML — I would need to convert them to Apple’s .mlmodel format, and the process to do that conversion today is complex and time-consuming. As a result, it’s very unattractive for a proof of concept. Since any good news on this front is at least a few months away in WWDC 2025, I had to find another way to experiment.
The Workaround
While on-device Core ML-based inference isn’t feasible for me right now, that doesn’t mean that Apple silicon native inference isn’t. Enter Ollama. Ollama allows me to host and run inference on open-source language models locally on my M1 Pro Macbook Pro (thanks Apple for that great naming scheme), along with exposing an API for me to build off of. For the purposes of this article I used either phi4-mini or gemma3:4b small language models to simulate what might be possible on an iPhone.
Architecture
The setup to use a locally networked Ollama inference server in my app is relatively straightforward — here’s my stack:

This setup allows me to pull models from Ollama, host them on Apple silicon not all that different from a modern iPhone (RAM not withstanding) and interact with them over the network from my budgeting app. Changing out models is as simple as changing one line of config code, so I can rapidly test a whole host of models without complicated model format conversions. Let’s start from the top.
User Experience
UX is the core of any app, and to keep mine simple, I implemented a messaging-style UI that follows familiar patterns for an AI chat experience:
- A section for users to type and send their prompt to the assistant
- Persistent chat history for context continuity
- Support for follow-up questions that maintain conversational context
- Ability to clear context and start fresh via a simple button
When put together, those elements create a user experience of simply chatting with a financial assistant, while the complex data extraction, context management, and inference processes are executing behind the scenes. It looks a little something like this:

With the frontend and backend now taken care of, I needed to get the messy middle figured out —allowing them to talk to each other.
The Communication Layer
Getting the communication layer stood up actually wasn’t too bad — Ollama’s API doc was useful, and there was plenty of support resources on the web. To stay consistent with user’s expectations of how AI chat experiences work today, I went the route of streaming the model’s response back to my app instead of displaying a loading icon until the response was complete. The heart of my implementation looks like the following:
// Generate a streaming response from the Ollama API
// - Parameters:
// - prompt: The user's prompt
// - systemPrompt: Optional system instructions
// - onToken: Callback function that receives each token as it arrives
// - onCompletion: Callback function that is called when the response is complete
func generateStreamingResponse(
prompt: String,
systemPrompt: String? = nil,
onToken: @escaping (String) -> Void,
onCompletion: @escaping (Result) -> Void
) {
let fullPrompt = formatPrompt(userPrompt: prompt, systemPrompt: systemPrompt)
let request = GenerateRequest(
model: modelName,
prompt: fullPrompt,
stream: true,
options: GenerateRequest.Options(
temperature: temperature,
topP: topP,
numPredict: maxTokens
)
)
Task {
do {
// Create URL request
let url = baseURL.appendingPathComponent("generate")
var urlRequest = URLRequest(url: url)
urlRequest.httpMethod = "POST"
urlRequest.addValue("application/json", forHTTPHeaderField: "Content-Type")
urlRequest.timeoutInterval = 60.0
let encoder = JSONEncoder()
urlRequest.httpBody = try encoder.encode(request)
// Start streaming session
let (stream, _) = try await URLSession.shared.bytes(for: urlRequest)
let decoder = JSONDecoder()
for try await line in stream.lines {
guard !line.isEmpty else { continue }
// Each line contains a complete JSON response
if let data = line.data(using: .utf8) {
do {
let response = try decoder.decode(GenerateResponse.self, from: data)
onToken(response.response)
// Check if this is the final chunk
if response.done == true {
onCompletion(.success(()))
break
}
} catch {
print("⚠️ Error decoding JSON: \(error)")
onCompletion(.failure(error))
break
}
}
}
} catch {
print("⚠️ Streaming error: \(error)")
onCompletion(.failure(error))
}
}
}
After a good amount of troubleshooting and fixing, I was finally able to get HTTP 200 logs showing in my Ollama server terminal, and responses were returning to my frontend. They weren’t very good responses though.
Intelligent Context Management
It quickly became obvious that while I could ask the assistant questions, it didn’t have access to my data. This meant it was just making up responses to my questions. Manually providing data to the assistant in my prompt provided much better results, but that defeated the purpose of interacting with it, so I started thinking through different ways to give the assistant access to my data in the app’s CoreData store.
Retrieval augmented generation (or RAG) was my first thought for this scenario. However, setting up a vector database, embedding the user’s data, and making it available to the model via RAG is completely overkill for my app. I ruled this out about as quickly as I thought of it. The next best option I thought of was to utilize the model’s context window to load in relevant data.
For some context (ha!) — GPT3 initially had a context window of around 2k tokens when it went mainstream. Models today, even tiny ones, have a context window of 128k tokens or more. Knowing this, I figured I had much more context available to me than I was going to use for a chat session. I could probably just dump my whole CoreData store into context for the assistant to use, right?
Wrong. What I found in practice was:
- Even with just test data, the complicated relationships for my data used a lot more context than I assumed it would’ve. It all fit, but only barely, which means this wouldn’t work for a production implementation.
- The models couldn’t handle this amount of data and still give relevant responses — the rate of inaccurate and frustrating responses went through the roof.
I had to find some other way to provide only the most relevant data. Enter:
The Context Generator
The context generator’s purpose is to analyze keywords in user questions (e.g., “spend,” “budget,” “income,” “account”, etc.) and determine what financial data is relevant to provide to the model. Based on detected intent, the system then selectively pulls the data from the CoreData store. I also time-box this to the user’s currently selected year in the app as to not overwhelm the model with too much data.
This approach provides what I believe will be sufficient context to answer most questions, but is clearly lacking for larger context applications such as year-over-year comparisons. It’s also very brittle, and not something I intend to support long-term. You can see some of how I’m doing this here:
func getBudgetContext(for query: String, context: NSManagedObjectContext) -> String {
var budgetContext = ""
// Add budget summary data (always included)
budgetContext += getBudgetSummary(context: context)
// Analyze query and add relevant data
let queryAnalysis = analyzeQuery(query)
// Add query-specific data based on keywords
if queryAnalysis.needsSpendingDetails {
budgetContext += getSpendingDetails(context: context)
}
if queryAnalysis.needsCategoryDetails {
budgetContext += getCategoryDetails(context: context)
}
if queryAnalysis.needsIncomeDetails {
budgetContext += getIncomeDetails(context: context)
}
if queryAnalysis.needsAccountDetails {
budgetContext += getAccountDetails(context: context)
}
if queryAnalysis.needsUpcomingTransactions {
budgetContext += getUpcomingTransactions(context: context)
}
return budgetContext
}
// MARK: - Query Analysis
private struct QueryAnalysis {
var needsSpendingDetails = false
var needsCategoryDetails = false
var needsIncomeDetails = false
var needsAccountDetails = false
var needsUpcomingTransactions = false
}
private func analyzeQuery(_ query: String) -> QueryAnalysis {
let lowercasedQuery = query.lowercased()
var analysis = QueryAnalysis()
// Spending keywords
let spendingKeywords = ["spend", "expenses", "cost", "paid", "purchase", "bought"]
analysis.needsSpendingDetails = spendingKeywords.contains { lowercasedQuery.contains($0) }
// Category keywords
let categoryKeywords = ["category", "budget", "allocation", "limit"]
analysis.needsCategoryDetails = categoryKeywords.contains { lowercasedQuery.contains($0) }
// Income keywords
let incomeKeywords = ["income", "earn", "salary", "revenue", "money", "paid"]
analysis.needsIncomeDetails = incomeKeywords.contains { lowercasedQuery.contains($0) }
// Account keywords
let accountKeywords = ["account", "balance", "bank", "savings", "checking"]
analysis.needsAccountDetails = accountKeywords.contains { lowercasedQuery.contains($0) }
// Upcoming transaction keywords
let upcomingKeywords = ["upcoming", "recurring", "future", "next", "planned", "scheduled"]
analysis.needsUpcomingTransactions = upcomingKeywords.contains { lowercasedQuery.contains($0) }
return analysis
}Prompt Engineering
With context now being provided, I needed to shape the model’s responses to user inquiries. The system prompt is where I’ve primarily been addressing this, and it’s been an interesting exercise — my first iterations made the model’s responses nonsensical, too long, and overly flowery. Subsequent iterations reversed that behavior and made it too short and rigid. Eventually, I landed on a relatively useful system prompt:
// Helper function to create the system prompt
private func createSystemPrompt(with context: String) -> String {
"""
You are a friendly budget assistant for a personal budgeting app. Provide clear, helpful insights about the user's finances.
Here is the user's financial data:
\(context)
RESPONSE GUIDELINES:
1. Be concise but warm - aim for 3-5 sentences for most responses. Do not overuse exclamation points or excessive congratulatory statements
2. Lead with the most important financial fact or figure
3. Balance accuracy with approachability
4. Support answers with specific numbers from the data
5. Use a conversational but straightforward tone
6. For complex information, use short bullet points
7. Offer one practical suggestion WHEN RELEVANT
8. Avoid unnecessary technical jargon
9. If the user asks for specifics for things like their income or expenses, be comprehensive in your response
10. Do not offer a recap of the information you've already provided
11. Make it clear when you're referencing data from a specific month or the entire year (e.g., "In March 2025, your expenses were..." or "For the entire year of 2025, your total income was...")
12. Do not provide excess information - if the user wants to know specifics of a particualr month, category, type of transaction, etc. do not provide information that doesn't fit their inquiry
"""
This system prompt generally keeps the model anchored to its role, the financial data provided to it, and how to best respond in a way that a human might appreciate. I’m still far from considering myself proficient in system prompt writing, though!
End result
When everything is put together, the experience looks like this:
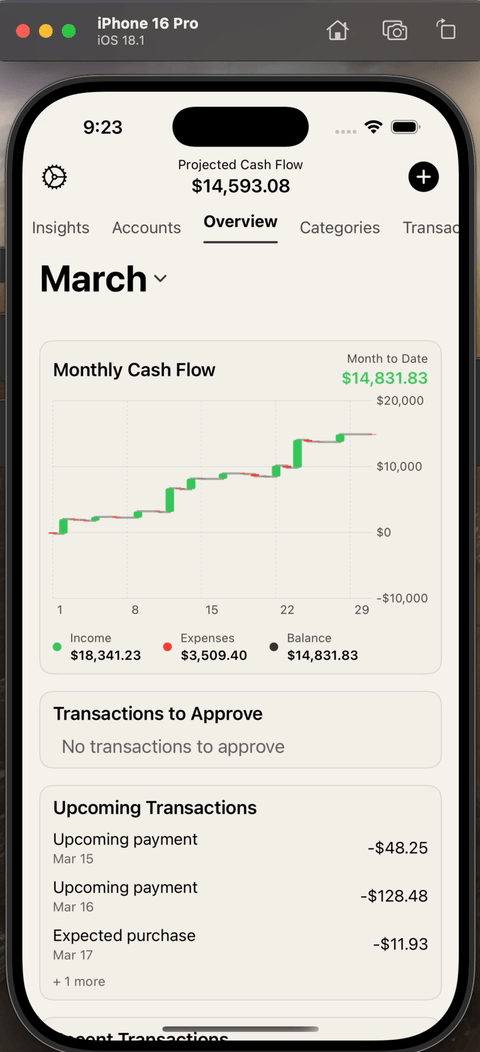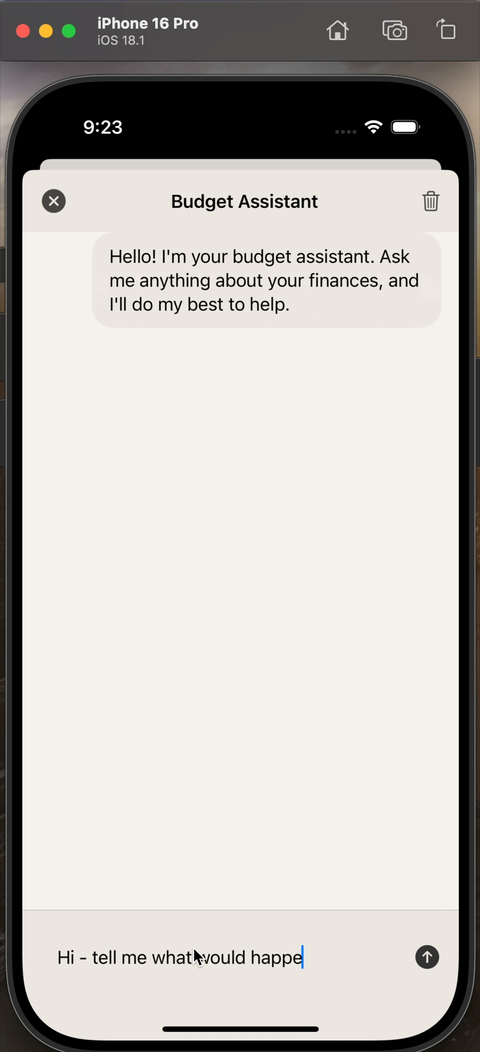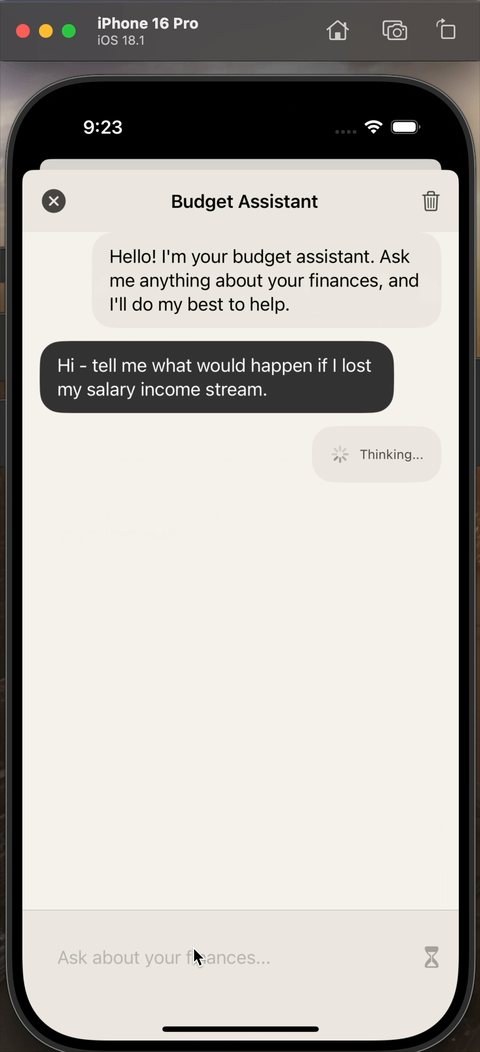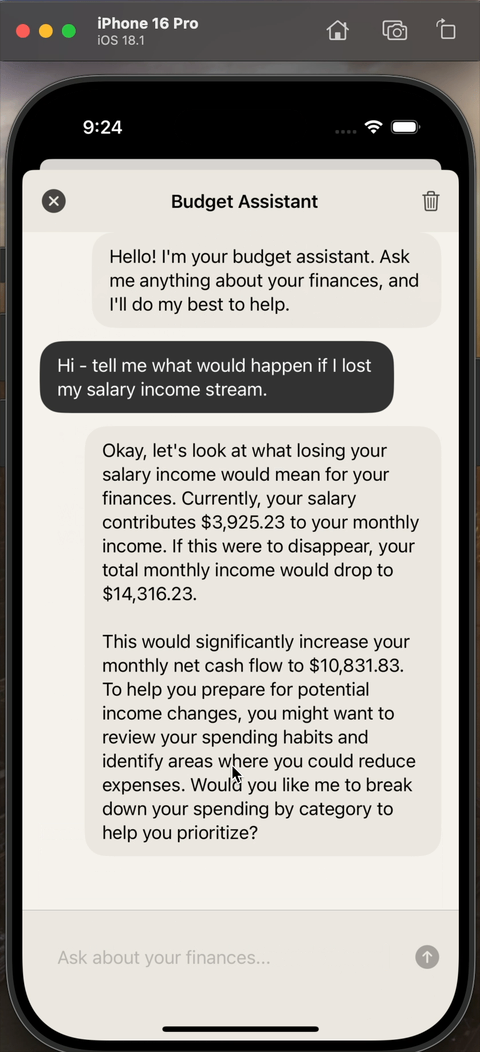
Downsides
While this proof-of-concept is promising, it has significant limitations:
Dependency on Ollama and the Local Network
Obvious callout — this approach requires Ollama and my client device running on the same network, or for the client to be VPN’ed in to my network. This is not my ideal end-state as I’d like this to be fully local on my iPhone, but it is sufficient to experiment with for now.
Limited Context
Since the current implementation only has a relatively small amount of context to work with via the user prompt and context generator, it’s not fulfilling it’s true potential. I have some ideas on how to address this shortcoming (like model tool use), but we’ll see how far those options are able to go. With models this small, I suspect the results won’t be great.
(Other) Small Model Problems
We’ve seen incredible improvements for tiny models, and they’re generally useable now, but they’re still not very good. In my testing they often confuse basic things such as the difference between income and expenses, and you can generally only get a handful of prompts in before it starts to go off the tracks.
Inconsistent Performance
Response times vary from 2–10 seconds depending on query complexity and system load, creating a suboptimal user experience. This experience is generally acceptable for now, but I assume the clock is ticking until the responses need to be near-instantaneous.
Limited Financial Expertise
While tiny models understand financial concepts, they lack the depth of knowledge that a specialized financial advisor would have. I hope this improves with future models.
Wrap Up: Why This Matters
In the end, this experiment demonstrates that useful, privacy-preserving AI isn’t just theoretically possible — it’s achievable today. As the process to get language models running on edge devices improves, model compression techniques advance, and mobile hardware capabilities shift to prioritize on-device AI, local inference will become increasingly viable.
On the flip side though, I could just continue this approach and utilize much larger models on my networked inference server. A reasoning model makes a lot of sense for this use case, and I don’t see those being feasible on an iPhone any time soon.
Regardless, I’m looking forward to what the future brings — a personal finance agent that completely eliminates the manual part of budgeting is my endgame, and hopefully we start to see green shoots for those experiences later this year.
Thanks for reading! Drop a comment or interact with the article if you enjoyed it.