

Deep Research using GPT-4o and Tavily

https://llm-deep-research.streamlit.app/
OpenAI recently launched a powerful new tool called Deep Research for their Pro users. It was designed to revolutionise how complex, multi-step research tasks are performed…
…for a whopping USD200 per month!

What is Deep Research?
According to OpenAI’s own marketing spiel , it is…
Deep research is OpenAI’s next agent that can do work for you independently — you give it a prompt, and ChatGPT will find, analyze, and synthesize hundreds of online sources to create a comprehensive report at the level of a research analyst. Powered by a version of the upcoming OpenAI o3 model that’s optimized for web browsing and data analysis, it leverages reasoning to search, interpret, and analyze massive amounts of text, images, and PDFs on the internet, pivoting as needed in reaction to information it encounters.
In essence, it functions as an agent that researches across disparate sources of information and organises the findings into a structured report.
Deep Research vs. Reasoning Models
Deep research models specialise in information synthesis and multi-step research tasks.
Reasoning models, on the other hand, excels in logical problem-solving and complex reasoning tasks. But it can be overly verbose and become really “cheong hei” (long winded in Cantonese) …

Building the POC
When I started this project, I had a few goals:
- Use readily available libraries/frameworks whenever possible
- Create a simple front end
- Not forking out 200 Bacons 🥓
With these objectives in mind, I chose the following approach.
- Streamlit — Used as the frontend for users to input research topics, view generated responses and download reports in Markdown format. It also supports local testing with minimal setup.
- LangGraph — To be honest, I was new to this tool. What drew me to it was that I was able to manage directed acyclic graphs or DAGs (insert DAG joke here) workflow using natural language. Perfect for my use case!
- Tavily — A specialised search engine that handles searching, scraping, filtering, and extraction in one call. It comes with a generous free tier of 1000 credits which was ideal for my prototype. (About 30+ queries)
POC Workflow
I’ve kept the POC simple. The research process is divided into three primary stages:
1.User Input Stage: Users enter the research topic which initiates the research process
2.Planning and Research Stage: The system generates a structured research outline based on 5 key sections: Introduction, Current State, Analysis, Conclusion, References.
def _create_research_graph(self) -> Graph:
"""Create the research workflow graph"""
workflow = Graph()
# Add nodes for each step
workflow.add_node("plan", self._plan_research)
workflow.add_node("research", self._conduct_research)
workflow.add_node("write", self._write_report)
# Define the edges (workflow)
workflow.set_entry_point("plan")
workflow.add_edge("plan", "research")
workflow.add_edge("research", "write")
workflow.add_edge("write", END)
return workflow.compile()
def _plan_research(self, state: Dict[str, Any]) -> Dict[str, Any]:
"""Plan the research sections"""
prompt = ChatPromptTemplate.from_messages([
("system", """You are a research planning assistant. Create a structured outline.
Do NOT include a conclusion or summary section - this will be added separately at the end."""),
("user", "Create a research plan for: {topic}. Output ONLY a JSON array of sections, where each section has 'name' (string), 'description' (string), and 'research' (boolean) fields.")
])
...
...
...
sections = [
Section(
name="Introduction",
description="Overview of the topic",
research=False,
content=""
),
Section(
name="Current State",
description="Latest developments",
research=True,
content=""
),
Section(
name="Analysis",
description="Detailed analysis",
research=True,
content=""
),
Section(
name="Conclusion",
description="A detailed summary",
research=False,
content=""
),
Section(
name="References",
description="Source Attribution",
research=False,
content=""
)
]
For sections that necessitates further information, the application conducts targeted web searches using Tavily’s API. It then extracts and processes relevant content and synthesises the data with GPT-4o while maintaining source attribution.
3.Writing and Output Stage: The final stage involves compiling the synthesised content into a cohesive report, resulting in a polished and comprehensive document. An option to download the report in Markdown format is also available.
prompt = ChatPromptTemplate.from_messages([
("system", """You are a research assistant synthesising information from multiple sources.
Write in a clear, professional style. Follow these rules strictly:
1. Write in a flowing, narrative style that synthesises information from all sources
2. Focus on presenting the information clearly"""),
("user", """Write a comprehensive section about {topic}, focusing on {section_name}.
3. Use the information from these sources to inform your writing: {sources}
4. Write in a clear, professional style.""")
])
Extending Functionality
One of the advantages of this implementation is its flexibility to be expanded and integrated with additional features.
Below are three hypothetical scenarios to illustrate its potential.
Approach 1: Integration with Vector DB for RAG
The tool integrates with a vector database to improve the LLM’s responses by supplying contextually relevant information.
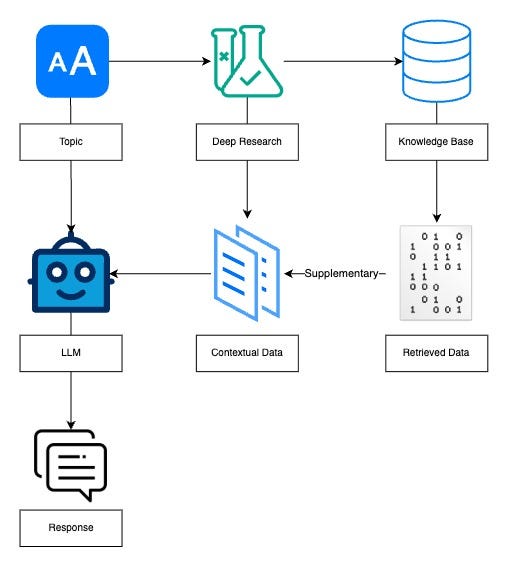
- The user inputs a query or topic
- Processes the prompt and retrieves relevant information
- Stores embeddings of the research data and queries the KB to find contextually similar information
- The retrieved contextual data is fed into the LLM as supplementary information to generate the response
Approach 2: Building a Proprietary Knowledge Base for RAG
A batch job processes multiple topics in parallel. The resulting output is embedded and stored in a knowledge base which is later used to provide contextual information for the LLM.
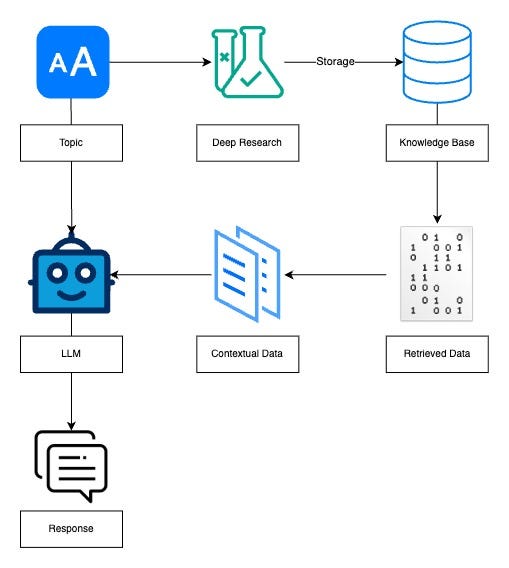
- The user inputs a list of topics for batch deep research processing
- The tool generates comprehensive research output based on the topics
- The research outputs are stored and indexed in a KB for future retrieval
- Relevant data from the KB is retrieved and provided as context to the LLM when the user initiates a research
Approach 3: Integration with Summarisation Features
A summarisation step is used to condense the content and emphasise key points from the research output.
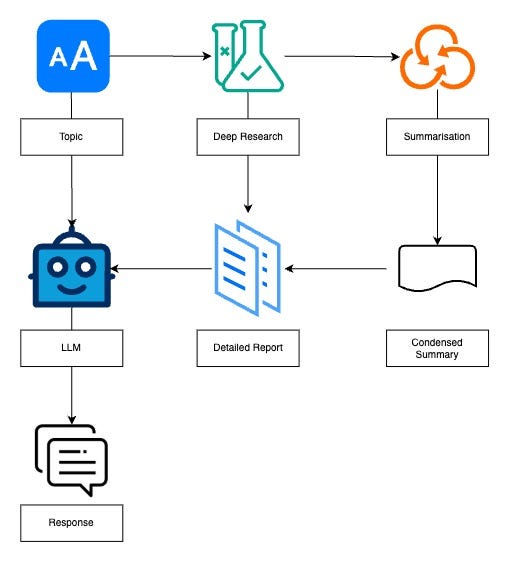
- The user inputs a query or topic
- Conducts thorough research and compiles a detailed report
- Takes the detailed report and distills it into a concise summary
- The summary is used as context for the LLM to generate a response
Use Cases in Public Service and Government
- Policy Development and Analysis
Government agencies can leverage the tool to conduct thorough analyses of policy options by compiling data from multiple sources. - Regulatory Compliance
Assists in monitoring and interpreting regulatory changes, potentially reducing manual and tedious compliance processes. Also helps to ensure adherence to evolving laws and standards. - Crisis Management and Disaster Response
Rapidly gathers and synthesises information from various online channels and priovide actionable insights to support timely responses. Especially for our Home Team during emergencies. - Public Communication and Engagement
Generates reports suitable for public dissemination. Helps build trust between government agencies and citizens through consistent communication. - Job and Skills Economy
Curates insights on global job market trends and economic trends. Helps government agencies design effective employment assistance programs. - Public Sentiment
Identifies recurring issues or areas for improvement by evaluating citizen feedback from multiple sources. The could potential lead to improved public service efficiency and citizen satisfaction.
Feel free to explore the demo at https://llm-deep-research.streamlit.app/.



References
- AI-powered research? OpenAI’s deep research explained
- https://www.forwardfuture.ai/p/deep-dive-unpacking-google-and-openai-s-revolutionary-deep-research-tools
- https://openai.com/index/introducing-deep-research/
- https://www.fastcompany.com/91271738/openai-reveals-new-ai-tool-that-can-do-online-research-for-you
- https://www.youreverydayai.com/deep-research-throwdown-perplexity-vs-google-vs-openai/
Deep Research using GPT-4o and Tavily was originally published in Government Digital Products, Singapore on Medium, where people are continuing the conversation by highlighting and responding to this story.