

API Testing Showdown. Postman vs Pytest. Part 4
Hello and welcome to part 4! This time, we will try verification against DB and some pytest features that are hard to imagine in Postman: marks, parameterizations, hooks, and plugins.
The previous parts of this comparison are here: part 1, part 2, part 3.
Verification against DB
I’ve worked on projects ranging from e2e tests without database interaction to those heavily relying on databases. If you’re focused on databases, you’ll likely need to gather datasets directly from them.
In Python (e.g., with pytest), many third-party libraries provide access to a database. To pull a list of worlds from SQLite, you can easily use the SQLite3 library.
@pytest.fixture()
def db_worlds(db_path):
connection = sqlite3.connect(db_path)
cursor = connection.cursor()
cursor.execute('SELECT * FROM world')
worlds = cursor.fetchall()
yield worlds
connection.close()
The same applies to most other DBMS. Postman doesn’t allow direct database access, so you’ll need a workaround, either self-written middleware or a plug-and-play third-party solution.
Examples of 3rd party solutions for SQLite:
ArrestDB is a lightweight open-source tool, while DreamFactory is a feature-rich platform for API development. Both serve as middleware for database access during testing.
You can create your own tool using a Python REST API framework, but it can be time-consuming and risky, as untested middleware may contain bugs.
Marks
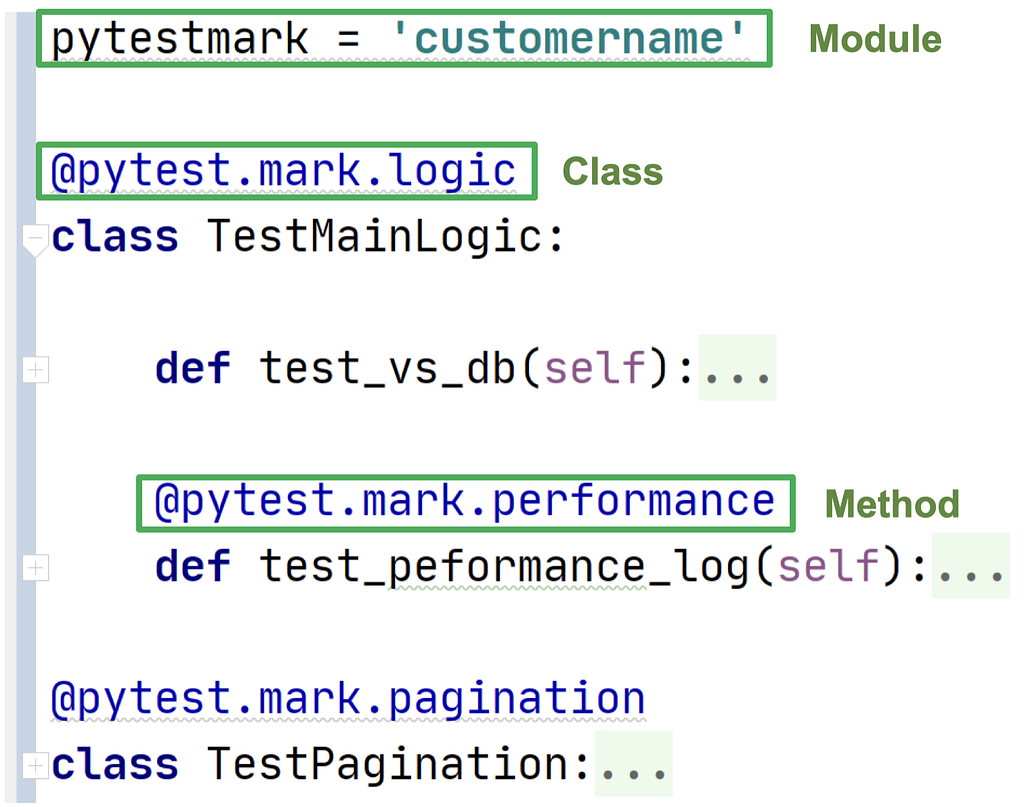
One of my favorite pytest features is marks. We can mark tests we want to run on a daily basis as “daily”…

…and run them via the -m parameter

As shown in the example, you can use logic operators like “and,” “or,” and “not” to create more complex test sets. Even better, you can mark an entire test class or module instead of marking each test individually.
In Postman, test suites can only be organized through folders, with no option for vertical slices like smoke or integration suites. I miss this feature.
Parametrization
Imagine you have the following set of test data
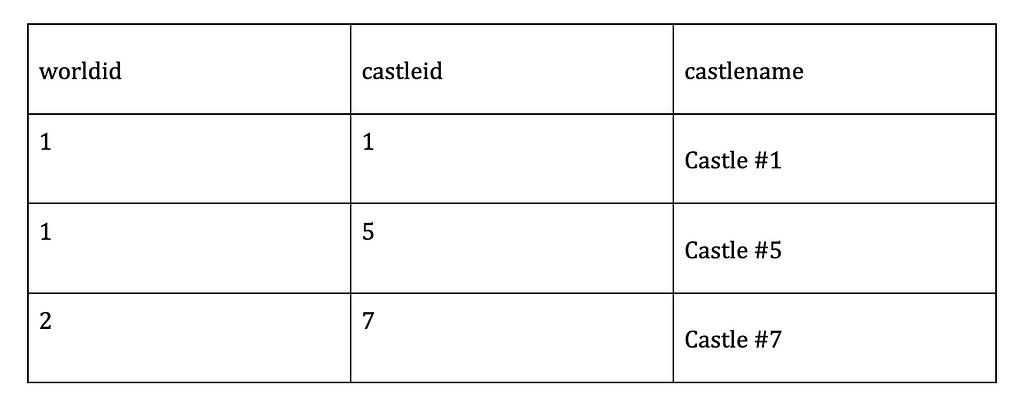
We could create separate tests for each case, but Postman and pytest let us handle a dataset within a single test. Let’s compare how they do this.
pytest.mark.parametrize
In pytest, you can use the @pytest.mark.parametrize decorator to pass a list of parameters and values to be processed.
test_data = [
(1, 1, 'Castle #1'),
(1, 5, 'Castle #5'),
(2, 7, 'Castle #7'),
]
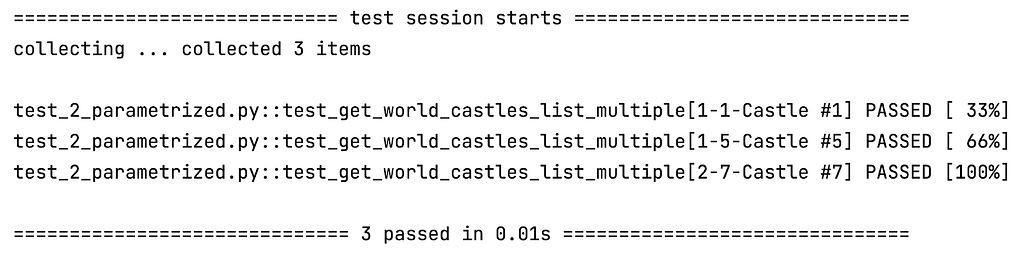
@pytest.mark.parametrize("worldid, castleid, castlename", test_data)
def test_get_world_castles_list_multiple(worldid, castleid, castlename, basic_url):
url = f'{basic_url}/world/{worldid}/castle/{castleid}'
response = requests.get(url)
assert response.ok
assert response.json()["name"] == castlename
Voila, you have a test that runs 3 times, each time with a new row of test data.
Postman data files
I cannot say that Postman data files are the same, but they are pretty lookalike features. Let’s try the same URL…

…and the same data set:
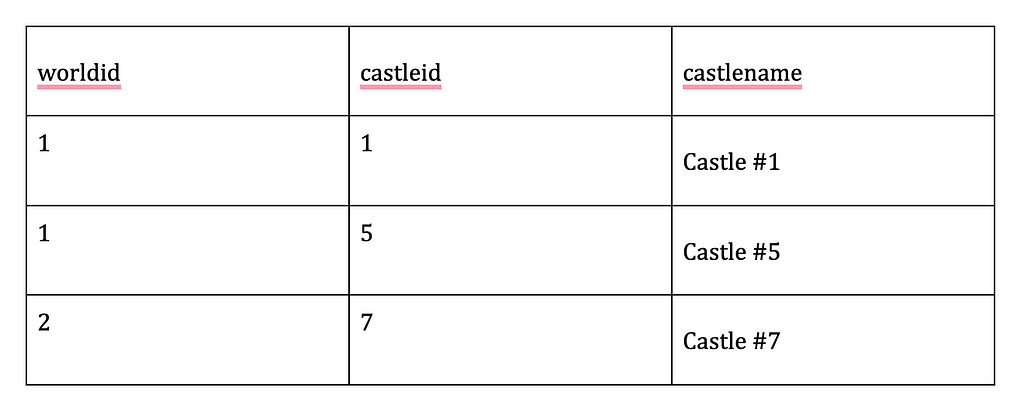
If you were wondering what the “data” variable level is…
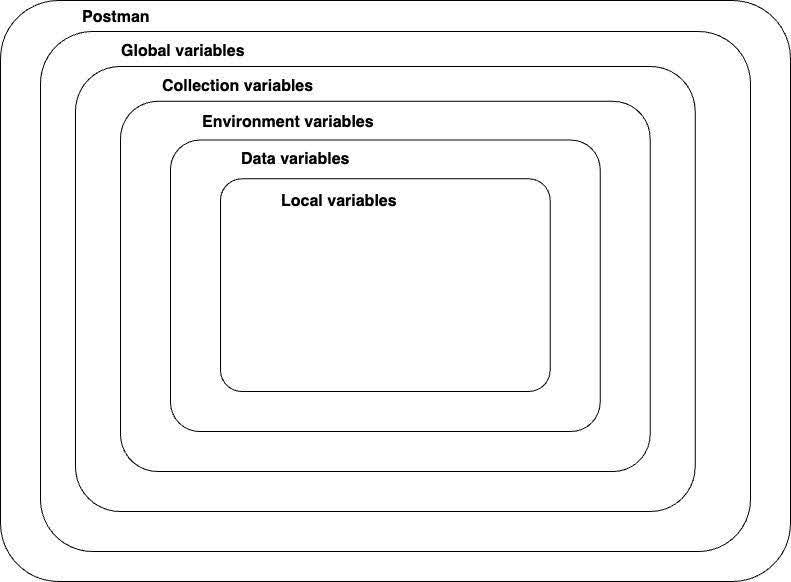
…here is the answer: you can load datasets in CSV and JSON formats right into Postman test runner, and thus, variables appear on this level.
When you execute a request, parameters from the CSV file are automatically inserted into the URL. You can also access the data from the code by calling the properties of the “data” object.
pm.test("Castle ID and Name are correct", function () {
var jsonData = pm.response.json();
pm.expect(jsonData['castle'][0]['id']).to.eql(data.castleid);
pm.expect(jsonData['castle'][0]['name']).to.eql(data.castlename);
});But you cannot run a request by simply clicking the “Send” button. You have to run its collection via collection Runner:
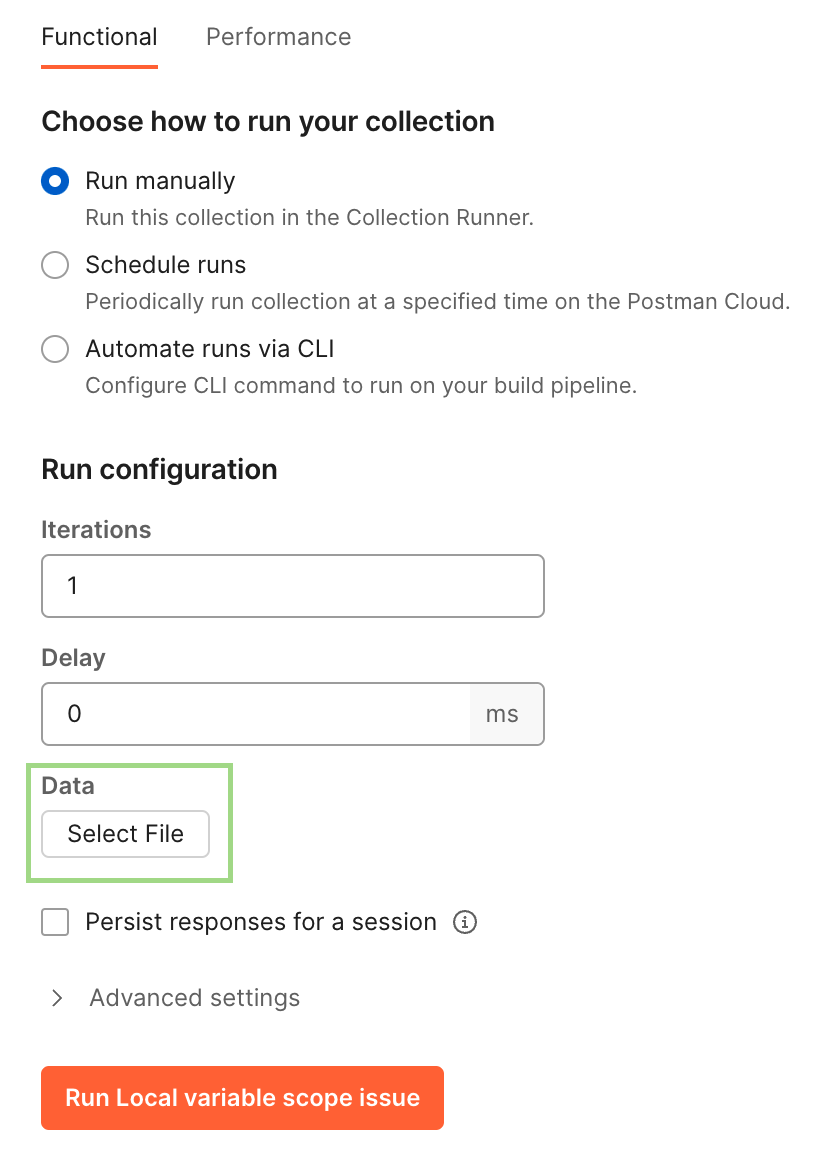
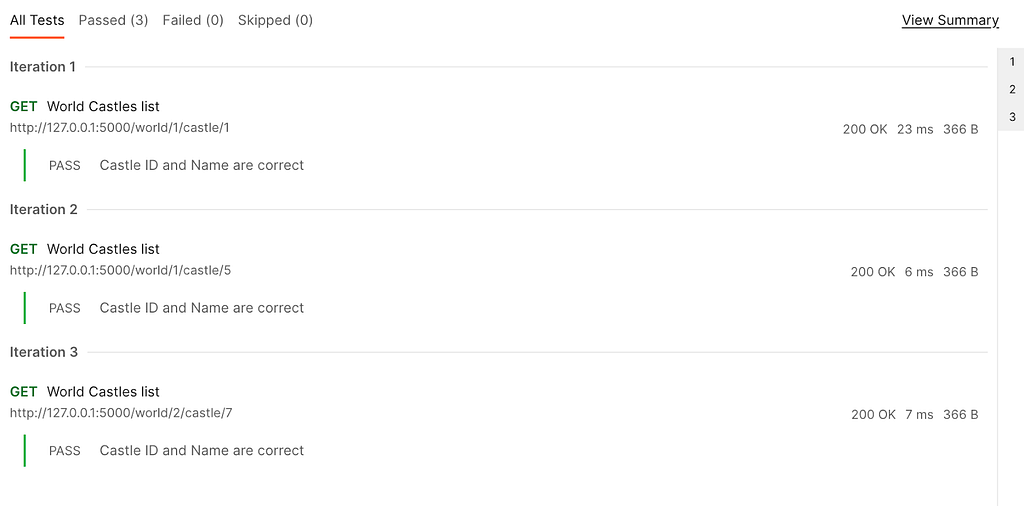
The parameters have been successfully passed to the URL and used in the test script to verify the response.
Pytest parametrize > postman parametrize
Since pytest is Python-based, you’re not limited to using simple integers or strings in parameterizations; you can pass any objects you like. I often use it to pass multiple Pydantic objects with user information and helper methods.
import pytest
import requests as requests
from pydantic.v1 import BaseModel
class Castle(BaseModel):
"""Model to show we can use custom types as field types too"""
name: str
...
class Goomba(BaseModel):
"""Model for our users"""
login: str
password: str
castle: Castle # here it is, our custom field type
...
def sign_up(self):
"""Wow, we can add methods too!"""
pass
@pytest.mark.parametrize(
"user",
[
Goomba(login="admin", password="admin", castle=Castle(name="Lancaster")),
Goomba(login="megagoomba", password="Qwerty1234", castle=Castle(name="Edinburgh")),
],
)
def test_with_user_in_parametrization(user):
response = requests.post("https://postman-echo.com/post", json=user.dict())
assert response.json()["data"] == user.dict()
Everything is readily available, and once you’re accustomed to it, you’ll likely prefer avoiding plain CSVs. Additionally, you can dynamically prepare test data within parameterization, pass test data to fixtures (indirect fixtures), define human-readable IDs, and much more.
Pytest hooks and plugins
Pytest allows you to manipulate its objects via hooks. This opens a whole new world for building complicated workflows and cutting corners.
Assume you want to process all tests inside a folder: mark all of them with pytest.mark or your favorite TMS decorator pytest_collection_modifyitems().
import allure
import pytest
def pytest_collection_modifyitems(items):
# Called after collection has been performed
# May filter or re-order the items in-place
for item in items: # items are inner pytest objects, representing tests
if "tests/auth" in item.fspath.dirname:
item.add_marker(pytest.mark.auth) # this is our regular pytest mark
item.add_marker(allure.suite("auth")) # here we add a decorator for a TMS report
Do you want to add a command line option?
def pytest_addoption(parser):
parser.addoption("--env", default="localhost", action="store", help="environment to handle")
You can now specify your environment from the CLI, though you’ll need to handle this variable in your code accordingly.
pytest --env prod
Do you want to alter parameterizations or even generate tests on the fly?
def pytest_generate_tests(metafunc):
# Allows to generate (multiple) parametrized calls to a test function
env_name = metafunc.config.getoption("env") # getting env_name from CLI option
url = envs[env_name] # getting url
if 'worldid' in metafunc.fixturenames:
response = requests.get(f'{url}/world') # collecting list of worlds "on the fly"
worldids = [world['id'] for world in response.json()['world')
metafunc.parametrize("worldid", worldids) # parameterizing calls
You can go even further, with numerous levers and options at your disposal. This also means there’s an extensive collection of ready-to-use pytest plugins available.
With features like parallel runs, reporters, linters, reruns, IDE integrations, and randomization control, there are many cool capabilities available with just a pip install. In contrast, Postman lacks this level of extensibility; you can’t create plugins, and using third-party libraries requires workarounds, as we’ve discussed before.
Conclusion
Pytest offers features that help maintain cleaner code, accelerate test development, and improve test run accuracy. By mastering these features and building a test framework, you can cover more ground in less time with less effort in code maintenance.
In the final, 5th part, I will explore some useful Postman features that aren’t directly tied to API auto-testing but can benefit QA engineers. I’ll also consider how to combine Postman and pytest to streamline our workflow and enhance quality.
API Testing Showdown. Postman vs Pytest. Part 4 was originally published in Exness Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.