

Think About Ai Systems Like A Tester
No matter what a system is, I like to diagram my understanding of it, breaking it into the parts and pieces and how they relate to each other. I always find that doing this makes it easier to understand where and how I want to focus my testing. AI systems are no different. Before we break them apart, we are often bewildered by what seems highly unpredictable behavior from the AI models. After we break them apart in a way that focuses how all the pieces fit together to solve the problem, the behaviors of the individual parts, including the AI models, start to show relationships that hint at how we want to focus on the testing.
I believe that most AI and ML based systems are modifications to a common pattern.
I describe that pattern in this article, and offer an example of it. The drawing below
illustrates both. I will describe it in more detail in the text that follows.
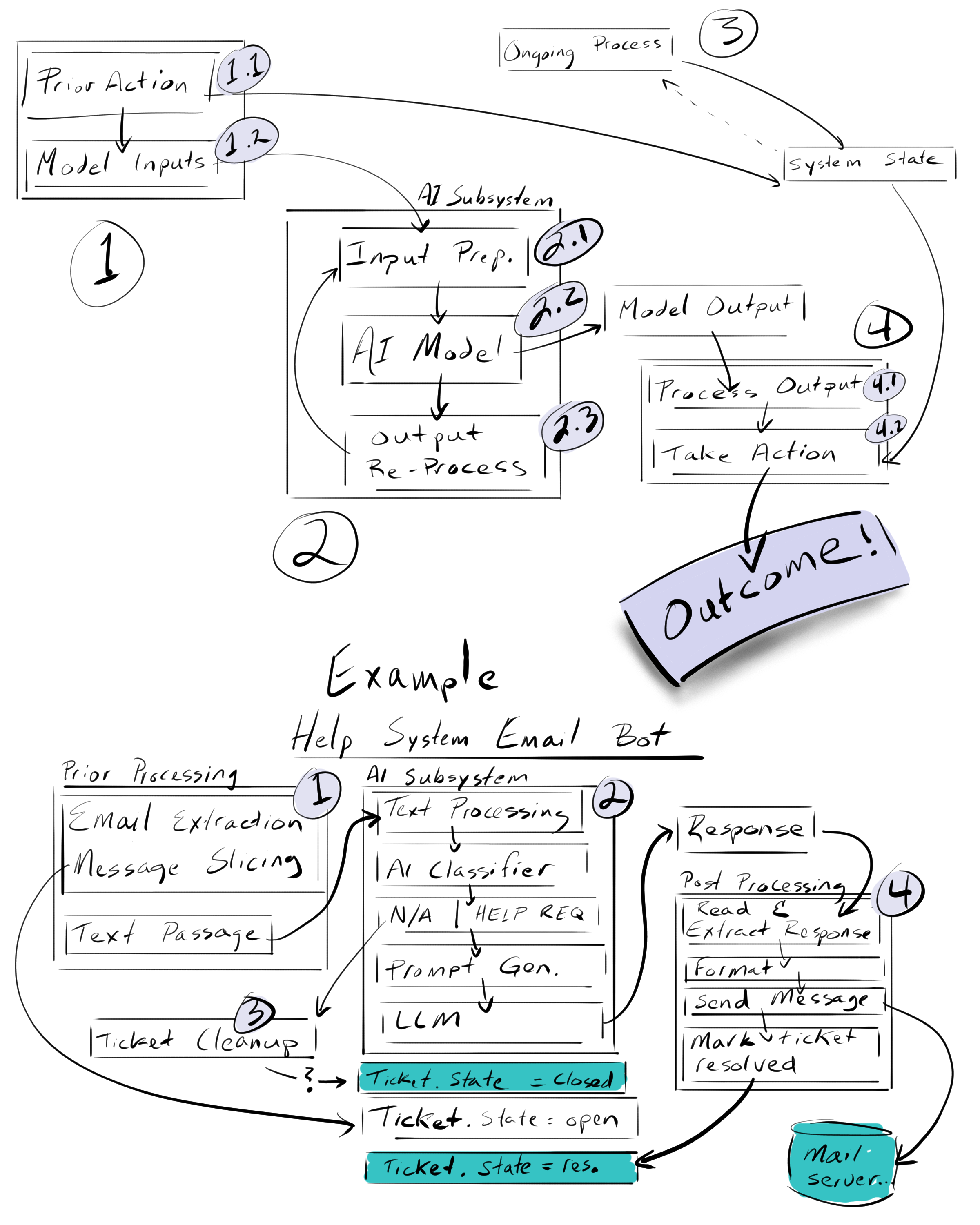
Short version, the system is comprised of four parts:
- anything that happens prior to AI processing which creates the input to the AI system, as well as changes to system state
- the AI processing of the input data to produce a response
- any background processing which may be affecting (non-AI) system state
- post processing of the AI response, and system state to produce an outcome
In this model, the “outcome” is we were usually decide if there is a bug or not. If the outcome cause a problem in some way, we have a bug. The data flowing through the system are the input to the AI, the system state outside the AI, and the response from the AI based on the inputs.
Before proceeding further, let’s talk about AI and ML models
It is important in this analysis to understand some fundamental differences between AI and ML models compared to code written explicitly. These differences are part of what makes test analysis of AI systems so daunting, but are make understanding how to approach the testing easier when we model the system as separate parts.
AI Models are statistical, most traditional code is not
We are used to thinking of code as solving problems deterministically. There is that joke which goes that a programmer’s spouse said to them “Go to the grocery store and buy a cartoon of milk. If they have eggs, get 12” and when the programmer returned home with 12 cartons of milk in response to the spouse’s inquiry why they bought that much milk, the programmer’s response was “They had eggs.”
This joke demonstrates something about conventional coding. It is deterministic, and blindly logical by formal rules. One can even imagine the code for the joke:
milk.cartons.buy(store.hasEggs() ? 12 : 1);
Because of the deterministic nature of the sort of code we are used to, we can even imagine a simple fix:
if (store.hasEggs()) {
eggs.buy(12); }
if (store.hasMilk()) {
milk.carton.buy(1); }
We find the broken case, change the logic, and the problem is addressed. We can accurately
predict the outcome of the above code based on a truth table for both hasEggs() and hasMilk()
(Actually, not really… what if the store has eggs, but less than 12? There is not enough information
in the code above for us to know what happens. But whatever it is, it is very likely deterministic and
the same for the same set of input values, we just didn’t account for a value.)
AI and ML models don’t usually work that way. Rather than having a deterministic relationship between a known set of inputs and the “correct” output, AI and ML models create outputs that on aggregate, over a large set, are correct a certain percentage of the time, and the models adjusted during training until that percentage hits an amount we find acceptable.
Imagine, for example, an AI model that is trained to purchase groceries based on the last purchases, the expiration date of what was purchased, and the current pantry/freezer/refrigerator contents. Sample data of human purchases correlating with those same inputs are fed to the model, and it is trained to 95% of the time buy the same items and number of items as the human 95% of the time. It will sometimes be wrong, perhaps not accounting for grocery shopping preceeding vacations (don’t buy perishables before leaving) or one off events (high school football team party at the house for all day barbecue, and there are heavy milk drinkers on the team), but it is usually correct.
The statistical nature of ML and AI models are a critical part of their behavior. We use them for problems that are fuzzy in nature because our deterministic, rule oriented approaches to solving problems do not adapt well to large numbers of inputs mixed with hidden variables. We can decide for ourselves where to draw the best fit predictions, but we have found that the training algorithms for AI and ML do the job faster, and better, than humans tend to for certain problems.
Remember that. We will get back to it.
Breaking down the model - email chatbot example
The idea of the model is to simplify the relationships between the system while also separating parts of the problem. Things happen at the beginning, are processed by AI in the middle, and then things happen at the end. While opportunities exist for things to go wrong at every stage, it is critical to understand how much is pushed onto the “beginning” and “ending” parts of the system.
We will use an example of an email chat bot that scans in inbox for messages, identifies help requests, generates responses to those requests via AI, sends a message and marks the issue as resolved when done.
Pre-processing (componet 1)
Pre-processing covers anythning that might happen prior to sending any information to the AI model subsystem. The key role of the pro-processing system is to generate the inputs to the AI system (step 1.2 in the model), but prior processing my create other system state that the AI model might not use, but which may have affect on later processing
For our email chatbot example, pre-processing monitors an inbox, breaks messages into pieces that are sized properly for the AI subsystem, and also creates entries in a ticketing system to track which messages have been processed.
AI Subsystem (component 2)
Most of the time inputs fed to an ai subsystem require some sort of preparation or processing before being fed to the AI model. Once prepared, the model produces a response. For some systems, that response may be processed further and sent through additional models - or even the same model (very common for LLMs to process data in steps through a series of prompts) before the final output is generated.
It is in the AI models, (step 2.2) where the statistical nature of the AI response comes into play. Generally all other parts of the system we think of as deterministic and predictable, we have an intention for what the inputs ought to produce as outputs. For the AI system, our intentions apply across the aggregate, we can know if lots and lots of response are doing what we want, but we don’t really know on a per response basis if the model is broken.
In our email chatbot, the text passages undergo text processing to make them suitable for the first AI model, a binary classifier trained to detect whether the passage is a request for help, or just not applicable. If the passage is classified as a help request, the the original passage is further processed and combined with a prompt that directs an LLM to produce an appropriate response/answer to the question in a json format for easy extraction. If the passage is not a help request, that information is made available for other background processes.
On-going processes (component 3)
On-going processes can change system state, and may do so in a way that is in conflict with response from the AI system. For example, if the AI system is a binary classifier choosing between class 1 and class 2, and if the ongoing process is setting some variable X as True or False, and if the combination “Class=2, X=False” is considered invalid, then the system might have a bug if the ongoing process and the AI classifier were to somehow produce that state.
In our chatbot example, the primary job of the ongoing process is to take the case where the classifier returns “Not Applicable” on the current process, and mark it as “CLOSED.” Imagine some bug in the system where the ongoing process marks the wrong message as “CLOSED,” or where even though the classification model returned “Not Applicable”, the message was still sent through for a response. This would result in a case where the final post-processing tries to respond to a ticket state that is “CLOSED” and set it to “RESOLVED”, which may not be a valid state transition.
Post-Processing (component 4)
The response from an AI/ML system is generally processed and drives some action. When the AI response is generate data, processing (step 4.1) often has to deal with the unpredictable nature of the AI subsystem output. Sometimes the content needed for further processing varies in format, or is surrounded by extra, undesired text. Sometimes the content isn’t there, replaced a spurious hallucination from the AI subsystem. The processing step should anticipate this possibility, expecting failure modes as an occasional norm rather than an impossibility that will eventually disappear once bugs are fixed. After processing, the system takes some kind of action (step 4.2). This is where content from the AI subsystem might cause further problems. An action indicated by the content of the response may result in an outcome that is undesired, permutations of the data from the AI system might combine poorly or in violation with system state, or data from the AI subsystem response may fall outside anticipated ranges cause an error or failure in the code taking action.
The highest risk potentional tends to be at the post processing state, because this is where all the inputs and state changes in the system come together to affect the final outcome. Errors introduced earlier will tend to propagate and ripple to this final stage. Not always. Sometimes something very bad could happen earlier, creating an early undesirable outcome, but the system has to get at least as far as processing inside the AI/ML model for us to think of this as an AI-derived problem.
In our email chatbot example, the response message is read, the json portion extracted and processed. The possibility exists that malformed responses (json missing, hard to extract, or in different schema) might cause failure in the processing engine - maybe it gets stuck, aborts, abandons processing that request. Those that are processed are formatted to look good in email - where some content might cause errors in the formatting code. After formatting, the message is sent to an email server, and the ticket state is changed to resolved.