

AI-Enhanced Web Scraping: The Story behind an AI Extension for Efficient Web Scraping

Introduction
Web scraping undeniably plays a crucial role in our information society, offering the ability to extract valuable data from various web resources.
In this article, I will share the journey of creating my product — a universal AI-powered web scraper, and delve into its key features. By harnessing the power of artificial intelligence, this tool not only automates the process but becomes a true fusion of technologies for rapid and intelligent collection of structured data. But first, let’s dive into the theory and history.

Classical Scraping
Classical scrapers are tools designed to extract data from web pages by analyzing and parsing HTML code. These applications operate based on predefined rules, indicating which elements of the page should be extracted and how they should be interpreted. Despite their popularity, classical scrapers are limited in their ability to adapt to changes in the structure of websites, requiring constant code updates with each alteration on the target page. This need for regular maintenance makes classical scrapers less user-friendly and sometimes inefficient in the dynamic web space.
I have extensive experience creating various scrapers in JavaScript. These tools interacted with both static content, extracting data from HTML using Cheerio or API responses, and dynamic content, requiring page loading using libraries like Puppeteer. From my experience, it became clear how often selectors needed adjustments or even a complete rewrite when the structure of a resource changed.
A similar challenge arises with extensions, where configurations specifying selectors for data collection are necessary.
Enter AI
With the advent of artificial intelligence, the opportunity to overcome these limitations arises. In my early experiments, I simply handed it HTML and asked it to gather the necessary data in the form of a table — and it worked!
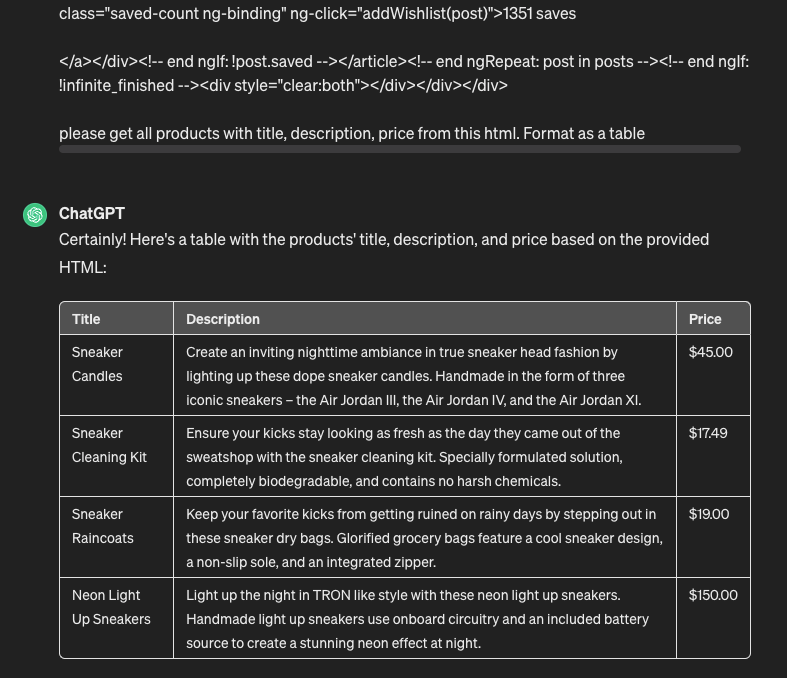
It was at this moment that the idea of creating an extension capable of utilizing these principles for scraping emerged. This is convenient since you are already authenticated on the required resource; there is no need to copy URLs or HTML, take screenshots, and so on. With just a few clicks, you can obtain the desired result without leaving the web page.
Development Kickoff
The first step in development was creating a simple collection in Postman. The initial request involved obtaining the HTML code of the target resource, which was then passed for processing in a subsequent request to the openAI API. This stage allowed me to validate the theory I shared in one of my posts, and I also wrote an article about it. Having received feedback, I proceeded to create a user-friendly frontend and made adjustments to the backend.
Creating a Demo
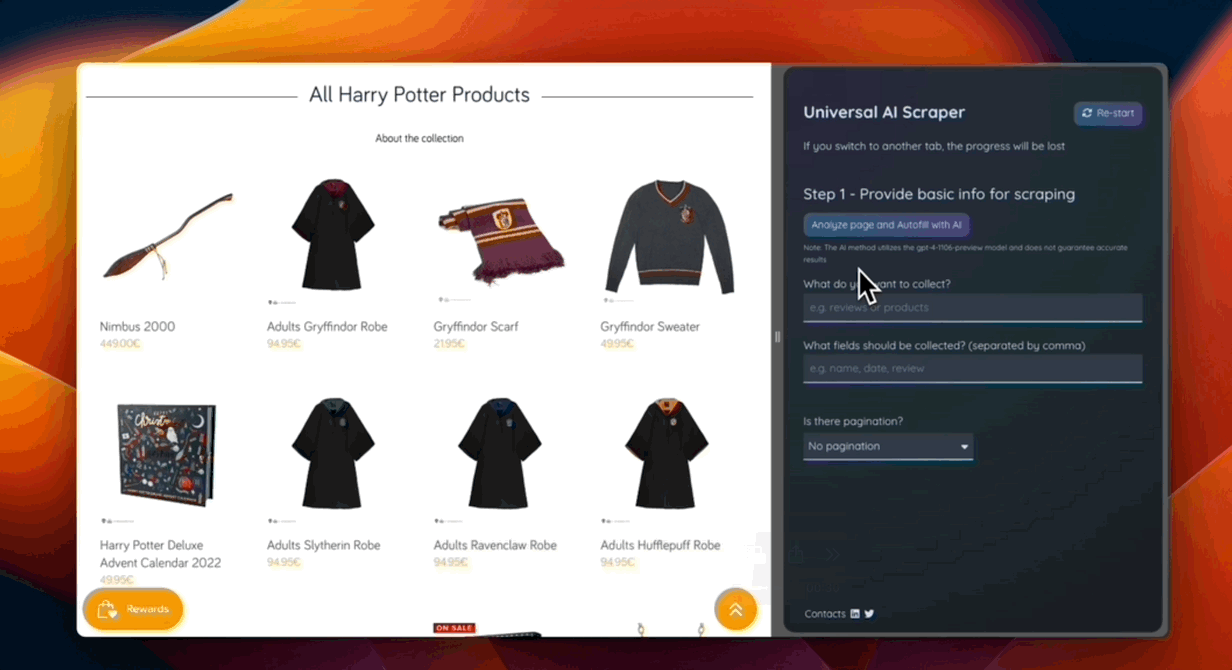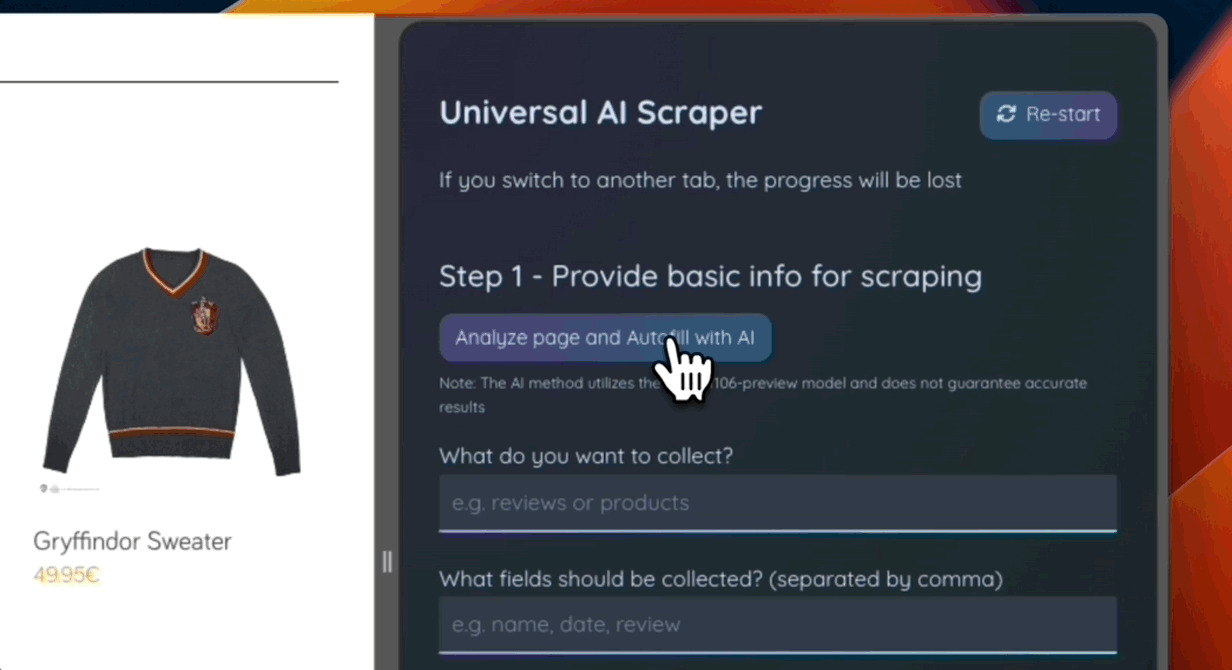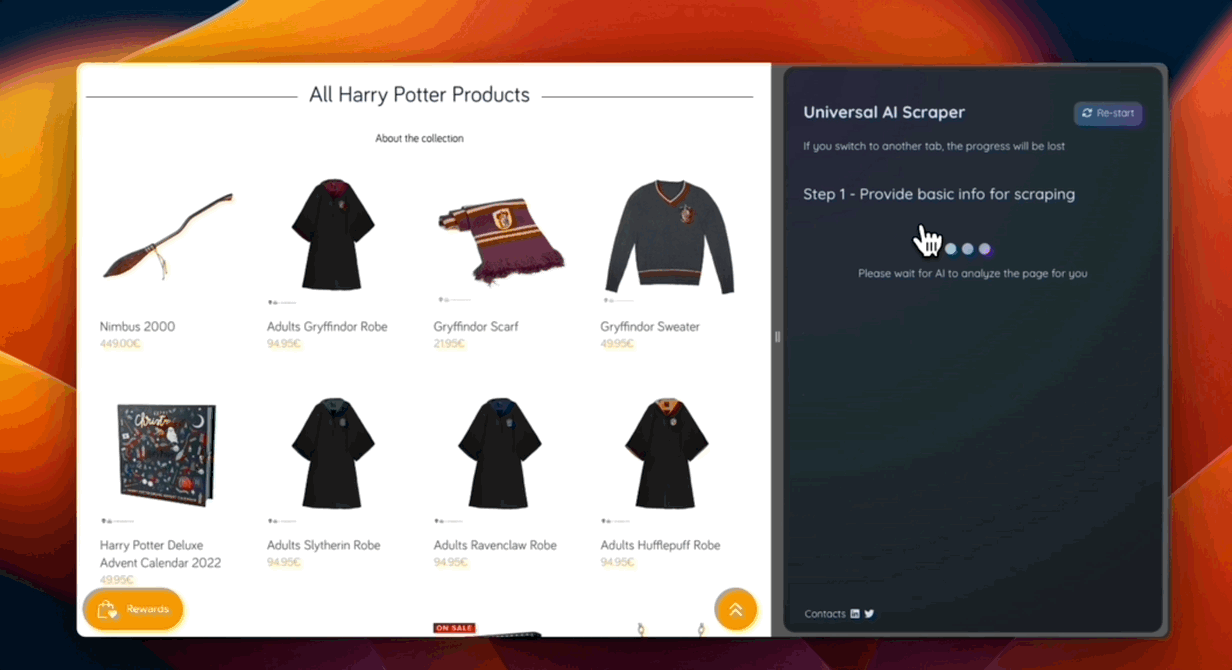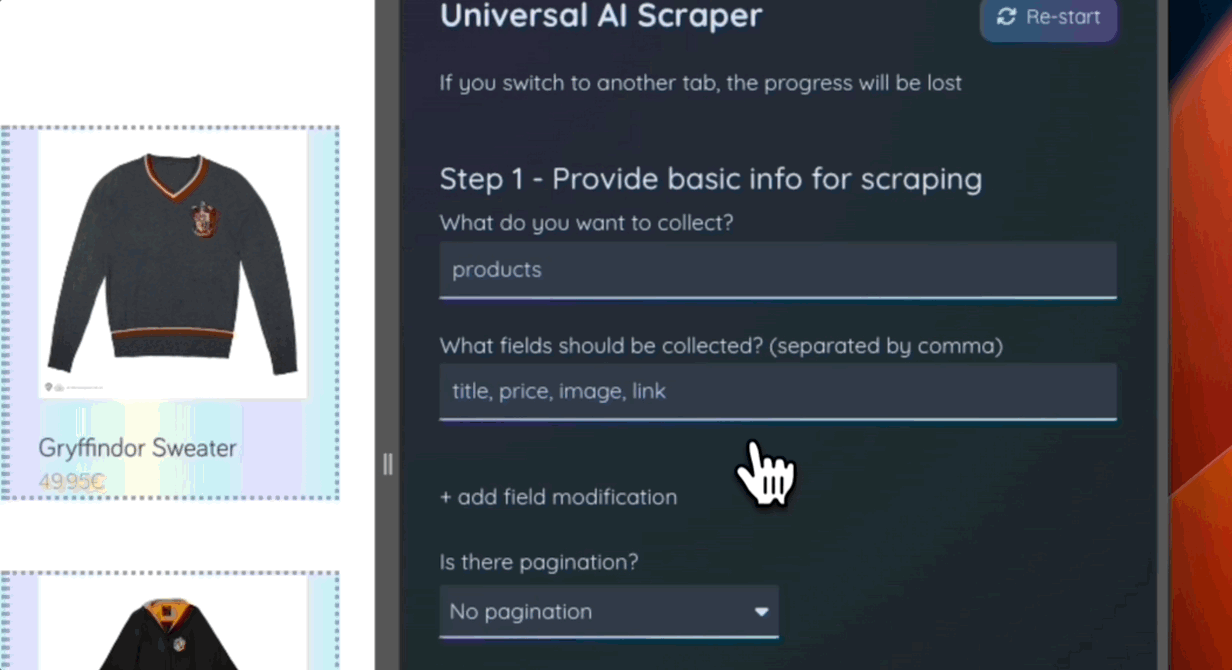
As part of the demonstration, I prepared a working extension capable of:
- Analyzing a web page to determine extractable data
- Finding elements containing the required information
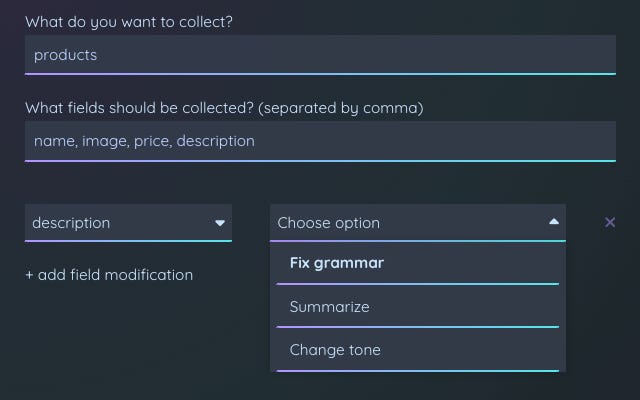
- Making on-the-fly modifications (changing the tone of text, correcting grammar, creating summaries)
- Collecting data
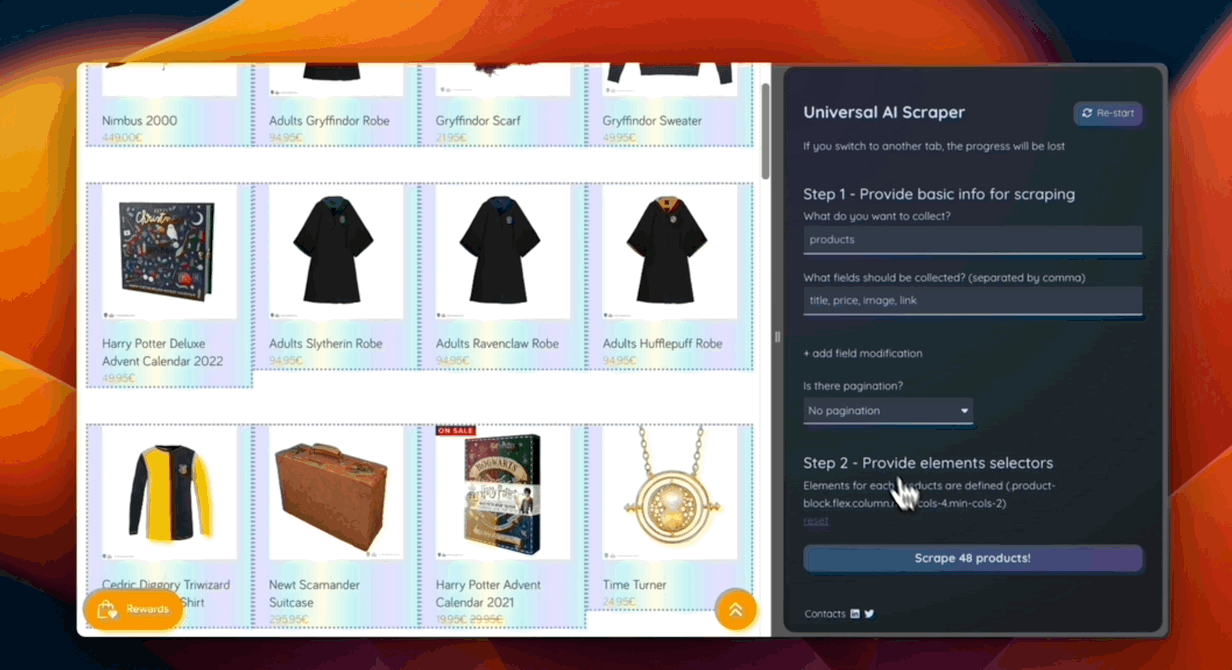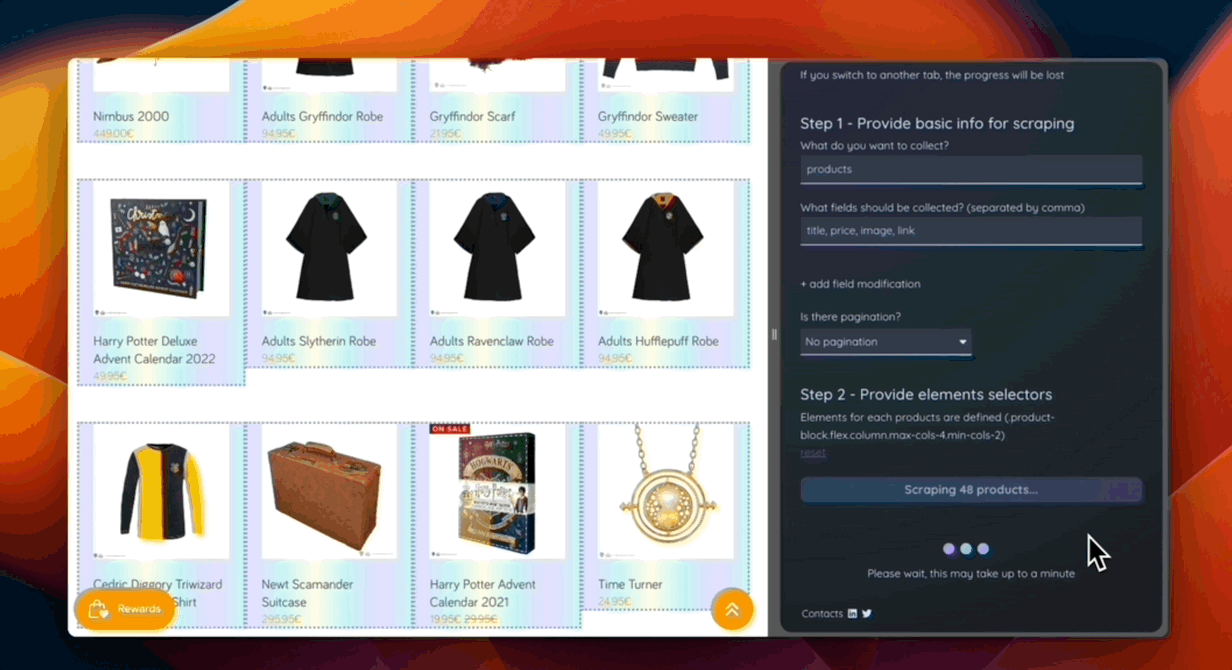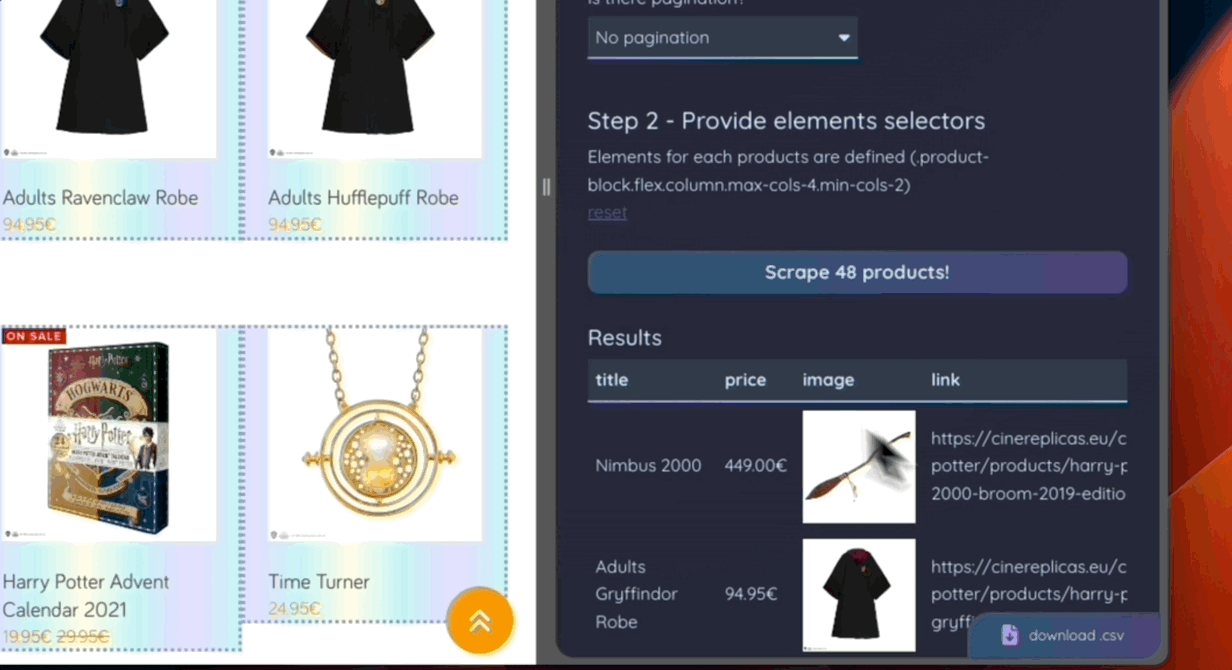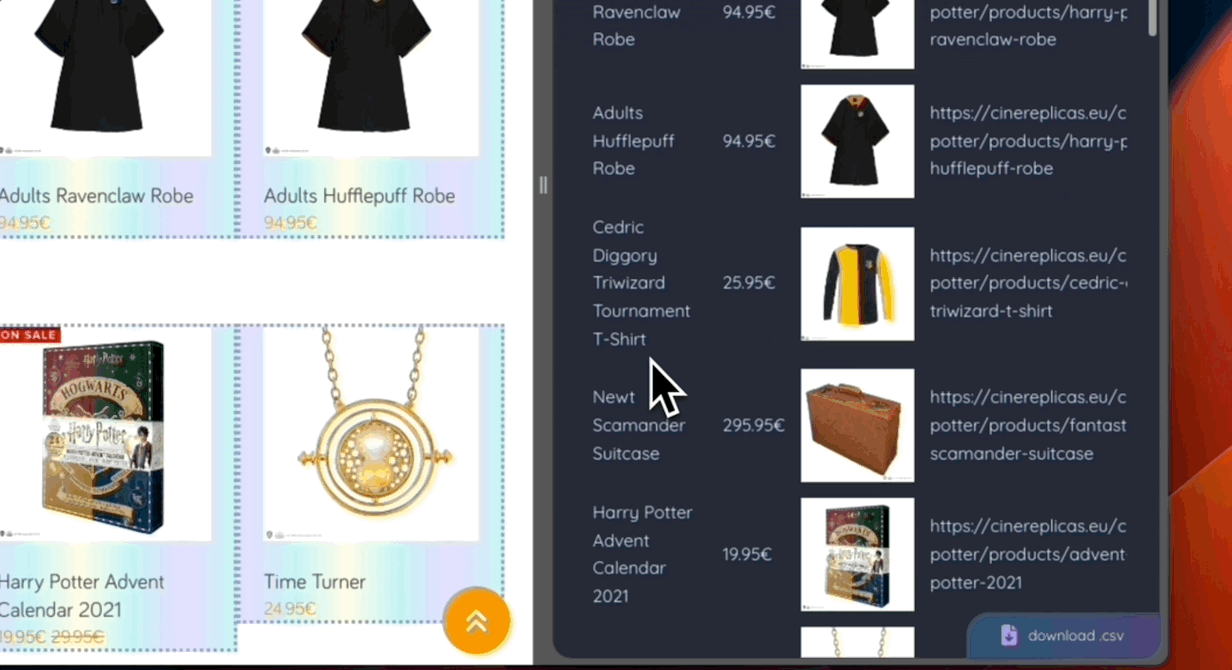
Thus, the entire scraping process is built on the use of artificial intelligence. You can check out the demo here.
Technical and Financial Aspects
My scraper operates on the openAI API, which, of course, imposes restrictions on the number of tokens and introduces a crucial aspect — cost. Before transmitting data to the openAI API, I preprocess the page, removing unnecessary attributes, comments, scripts, and other technical elements. Selector search is performed on a more limited version of the page (even text is truncated to 20 characters in each element) and is carried out iteratively. This allows passing the page in parts until the required information is found, significantly reducing costs. Selectors are necessary to retrieve information in parts, using a more cost-effective gpt-3.5-turbo-0125 model.
At this stage of development, I temporarily removed the automatic field search feature, which requires a model gpt-4–0125-preview, as it turns out to be quite costly. Currently, I am working on the possibility of implementing this function using a vision model cause it cheaper and return accurate results.
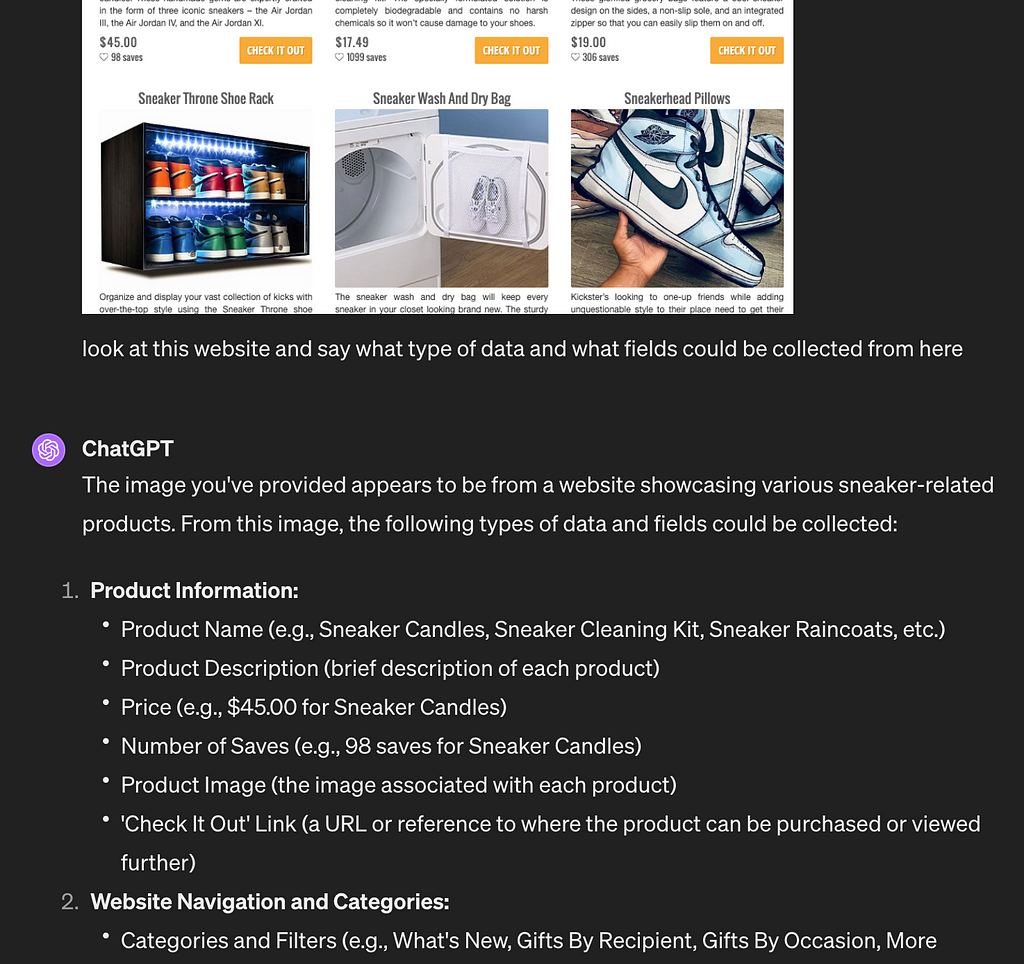
Audience Search and Feedback Analysis
However, like any product, it is crucial first to understand what the end user needs and direct the development of functionality based on these needs. I have many ideas, including transitioning to other language models, implementing image recognition, automatic data export to Google Sheets, result analysis, and much more.
Therefore, I invite you to try using the scraper. I would be grateful for any feedback you can leave directly through the extension’s form or by contacting me on any of the social media platforms.
Link: https://chromewebstore.google.com/detail/universal-ai-scraper/mfjniiodgjhlmleaakofgijfccdgppbc
Conclusion
Creating a universal AI-powered web scraper marks a significant step in the evolution of tools for data collection from the internet. Overcoming the limitations of traditional scrapers and extensions, this new tool, harnessing the power of artificial intelligence, demonstrates efficiency in the rapid, intelligent, and automated collection of structured data. But what the final product will be like, we will discover together. You can subscribe to me on Twitter and follow the scraper’s development.